En ocasiones mis clientes reciben archivos «extraños» que las herramientas TAO no reconocen, pues su extensión no figura entre las más habituales, y entonces me piden que busque una solución TAOísta para poder traducir el contenido de dichos archivos. En algunos casos, hay que buscar el modo de convertirlos a un formato intermedio que sí sea compatible con estas herramientas. Sin embargo, la mayoría de las veces, con un poco de maña, podemos crear un filtro para ese tipo de archivos que faciliten que la TAO en cuestión extraiga el contenido traducible. En esta entrada y en la siguiente veremos cómo crear nuevos filtros en memoQ y SDL Trados Studio 2017 y la forma de exportarlos para compartirlos con otros colegas o para usarlos en otro ordenador que tenga instalada alguna herramienta TAO. Si preferís saltaros la parte introductoria y ver directamente cómo crear nuevos filtros de archivos en Studio y memoQ, podéis ir a la siguiente entrada.
El primer paso: reconocer si el archivo contiene texto solamente
Lo primero que hay que hacer al recibir uno de estos archivos «extraños», por tonto que parezca, es probar suerte e intentar abrirlo con un editor de textos, como Notepad++ o el propio Bloc de notas. Dado que muchos archivos con extensiones poco frecuentes se utilizan en programación, se pueden modificar de una forma más o menos sencilla con cualquier editor de textos. También es posible que el propio archivo sea en sí mismo un archivo comprimido (como ocurre con los paquetes de Studio o los archivos MQXLZ de memoQ, por poner un par de ejemplos) y que entonces no se pueda abrir directamente con un editor de textos. En este último caso, basta con cambiar la extensión a ZIP y probar con un extractor de archivos para averiguar si es un archivo comprimido y, en tal caso, extraer los archivos que contiene.
En el archivo de ejemplo que usaré en esta entrada, me he inventado la extensión JM4. A pesar de ello, si trato de abrirlo con Notepad++, veremos que se trata de un archivo de texto no demasiado diferente de algunos con los que quizás ya nos hayamos topado antes, como en la siguiente captura de pantalla. Si el archivo contiene texto en un idioma que no sea el inglés y vemos caracteres que no se leen bien, la mayoría de veces solventaremos el problema cambiando la codificación a UTF-8. En Notepad++ podemos hacerlo eligiendo la opción correspondiente en el menú Codificación.
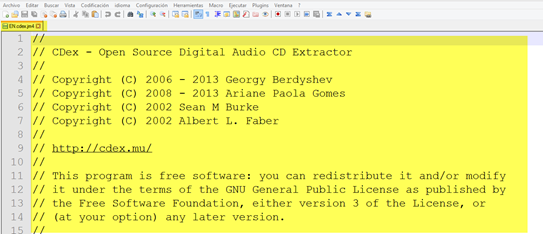
Un extracto del archivo con extensión poco habitual
Análisis previo del archivo
Antes de pasar a crear el filtro para este tipo de archivos, conviene analizar la estructura del archivo de origen con el fin de saber cuál es el contenido traducible y cuál es el contenido propio de programación que hay que aislar para que no se sobrescriba por error durante la traducción. Así daremos con la lógica empleada para separar cada elemento del archivo y podremos aplicarla en la herramienta TAO a la hora de crear el filtro. Empezaremos con la cabecera del archivo, como se observa en la siguiente imagen.
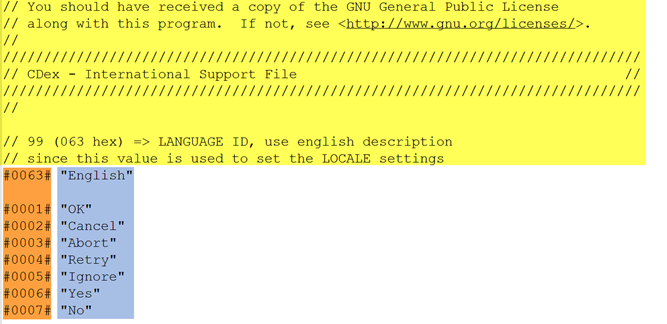
Cabecera del archivo
La sección señalada en color amarillo son líneas que comienzan con la barra lateral derecha (/). Echando un vistazo al contenido, podemos deducir que son comentarios añadidos por el desarrollador pero que no forman parte del código propiamente dicho. Por esta razón, se añade la mencionada barra lateral al principio de cada línea (siguiendo un patrón similar al que se ve en otros archivos de programación) o, dicho en lenguaje más técnico, «se comentan» las líneas. Lo más habitual es que no haya que traducir estos comentarios, pero, en caso de duda, no nos cuesta nada consultarlo con el cliente, pues pueden contener información valiosa para desarrolladores que sea recomendable traducir también.
En naranja vemos un nuevo patrón que se repite al principio de las siguientes líneas, que no es otro que el código o ID con el que se identifica cada cadena de texto. Dicho código tiene que quedar igual en el archivo traducido, por lo que lo aislaremos cuando creemos el nuevo filtro de archivo. A la derecha de este código, separado por un espacio y delimitado por comillas, se encuentra el contenido traducible. Una vez lo hayamos identificado, conviene seguir analizando el archivo en busca de secciones u otros elementos que sean traducibles pero que se desvíen de ese patrón, o bien elementos no traducibles dentro de las cadenas de texto.
La siguiente captura muestra algunos elementos muy habituales en archivos de este tipo:
- En amarillo, el símbolo et (&), que se añade delante de la tecla de acceso rápido. Podemos cambiarlo de sitio, pero siempre teniendo en cuenta que no puede usarse la misma letra para más de una tecla de acceso rápido dentro del mismo menú y que es mejor evitar las letras con tramos descendentes por debajo del renglón, como la ge y la pe, ya que el acceso rápido se muestra subrayando dicha letra.
- En azul tenemos un tipo de variable con el que se separan elementos dentro de una misma cadena de texto, ya sea por limitaciones de espacio u otras razones. En este caso, vemos el salto de línea (\n) y la tabulación (\t). Cuando traduzcamos cadenas de texto que aparezcan en más de una línea, aparte de tener en cuenta el límite de caracteres por línea (en su caso), hay que evitar la separación de sintagmas en la medida de lo posible, pues puede provocar problemas de fluidez al leer el texto (lo mismo que ocurre en subtitulación).
- Por último, los elementos señalados en naranja son variables, parámetros que no son fijos y que se establecen con datos aportados por el usuario del programa (en este caso, datos referentes a un disco, como el nombre del cantante y de la canción). Se ven a simple viste porque van precedidos de un delimitador, como el símbolo del porcentaje en este archivo. Al igual que las demás variables, tendremos que buscar un patrón para poder bloquearlas y que así el traductor o revisor no las elimine en un descuido.
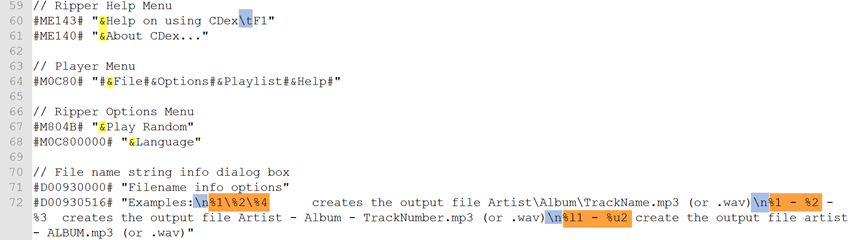
Nuestras amigas las variables
Ahora que ya conocemos el archivo de origen, toca pensar en cómo le indicaremos a la herramienta TAO de turno qué partes debe pasar por alto y cuáles debe importar para que se puedan traducir. En archivos como XML y HTML y sus variantes resulta más sencillo porque el texto traducible casi siempre está delimitado por etiquetas. Sin embargo, en este caso, hay que decirle a la herramienta TAO que este archivo sigue un patrón para separar el contenido traducible del no traducible.
Llegados a este punto, las preguntas clave son «¿Qué patrón sigue este archivo?» y «¿Cómo añadir este patrón a la herramienta TAO?». Nuestras «queridas» expresiones regulares serán nuestras mejores aliadas a partir de ahora. Aunque lo veremos en la siguiente entrada con más detalle, memoQ y Studio permiten crear filtros usando expresiones regulares. Dicho en pocas palabras, tenemos que indicar qué va antes y después del contenido traducible (ergo, todo lo que esté entre medias serán las cadenas de texto).
Antes de pasar a hablar de las expresiones concretas para este caso, tengo que aclarar que no soy ni mucho menos un experto en el tema, así que no me sorprendería que alguno de vosotros emplearais expresiones más precisas o más «bonitas». Dicho esto, a continuación os dejo las expresiones regulares que usaré como patrones de apertura y de cierre (dicho de otra forma, lo que va antes y después de dicho contenido):
–Apertura:
^#.+#\s{1,}»
Esta expresión, en lenguaje normal, equivale a: inicio de línea seguido de almohadilla, seguida a su vez por uno o más caracteres cualesquiera y una almohadilla. Después van uno o más espacios y comillas.
–Cierre:
«$
En lenguaje normal sería: comillas seguidas del final de línea.
-Variables:
Si bien solo los patrones de apertura y cierre son obligatorios, hemos visto que este tipo de archivos contienen variables que hay que mantener tal cual. Por tanto, es una buena idea convertir esas variables en etiquetas para que el traductor o el revisor no las omita en un descuido.
\\[a-z] = busca cualquier letra minúscula precedida de una barra lateral. Como la barra lateral es un carácter comodín en expresiones regulares, hay que añadir otra antes para indicar que estamos buscando el carácter literal en vez del comodín.
%[a-z]*\d = símbolo de porcentaje seguido por uno o cero caracteres de la a a la zeta minúscula y por un dígito.
Una vez tenemos claras las expresiones regulares que hay que añadir al filtro, solo nos queda utilizar una herramienta TAO para crearlo, como veremos en la siguiente entrada.
Deja una respuesta