Hace poco recibí una consulta de una compañera con respecto al manejo de ciertos datos en memoQ. En concreto, quería buscar el mejor método de ocultar en dicha TAO algunos datos sensibles (nombre y apellidos, DNI, correo electrónico, códigos de fármacos y ensayos clínicos, etc.) que los clientes buscaban proteger por cuestiones de confidencialidad. Esto se aplicaba especialmente en los casos en que las traducciones y revisiones se fueran a asignar a colaboradores externos.
Aunque hay diferentes formas de conseguir el objetivo —las cuales implican más o menos conocimientos técnicos y llevan más o menos tiempo—, en esta entrada nos centraremos en dos alternativas. La primera implica modificar los archivos de origen antes de importarlos en memoQ. En cambio, la segunda pasa por ocultar estos datos en memoQ tras importar los archivos de origen.
Primer método: usar un estilo de Word para los datos sensibles
Tras hacer algunas pruebas en memoQ, vi que el programa es capaz de ocultar información en los archivos importados siempre que esos datos tengan un estilo de Word que los distinga de otras secciones del archivo DOCX que sí son traducibles. Por tanto, se podría crear un estilo para este fin y luego solo habría que modificar el filtro de DOCX de memoQ para configurar ese estilo como no traducible.
Nuevo estilo en Word
Así pues, en este primer método empezaremos abriendo el archivo de origen en Word y viendo qué datos sensibles queremos ocultar. En la siguiente imagen los señalamos con sombreado amarillo.

Una vez identificados estos datos, creamos un estilo. Para ello, vamos a Inicio > Estilos en la cinta de opciones y pulsamos en la esquina inferior derecha para que se muestre el botón correspondiente. También podemos usar el atajo Alt + Ctrl + Mayús + S.
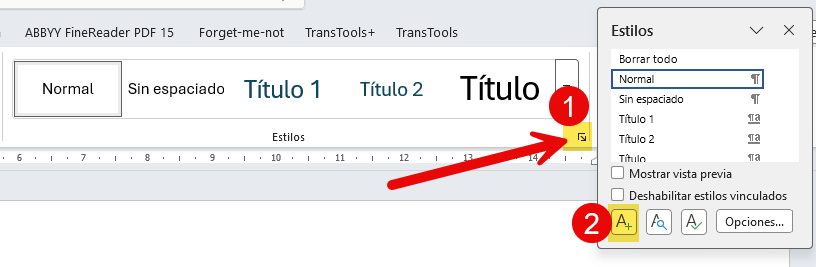
Ahora damos un nombre al estilo (por ejemplo, DatosSensibles) e indicamos que es un formato para párrafos enteros y caracteres (2). En su caso, también podemos darle un formato distintivo (3). En el archivo de ejemplo usamos el color azul para diferenciar el texto confidencial del resto.
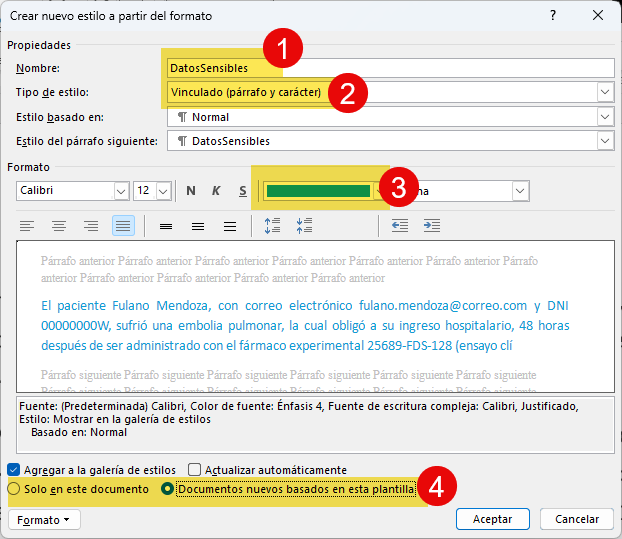
Por último, podemos decidir si solo usaremos el estilo para el archivo en concreto o si lo vinculamos a la plantilla (4), lo que evita que tengamos que crear el estilo cada vez.
Búsquedas y sustituciones de datos sensibles
Una vez creado el estilo, se lo asignaremos a todos los datos sensibles. Como es posible que haya muchos según el tamaño y otras características del documento, podemos usar los caracteres comodín de Word para buscar ciertos datos que siempre tienen el mismo patrón y asignarles el nuevo estilo en bloque.
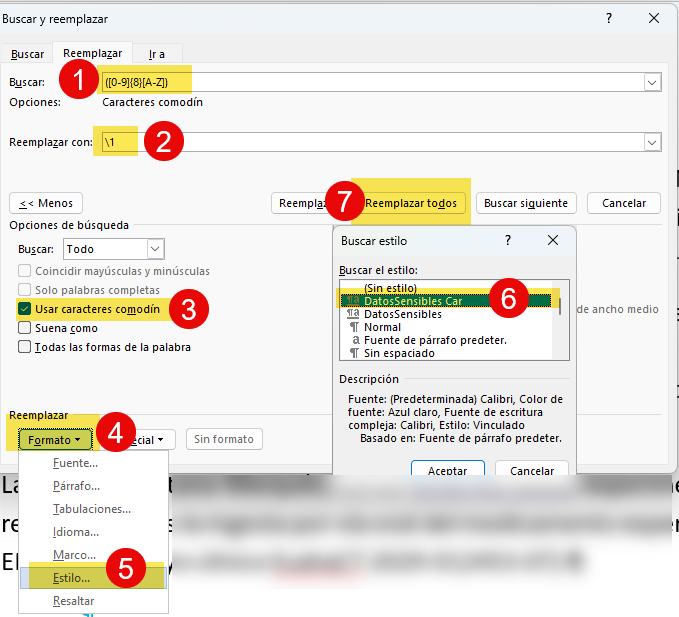
En la captura de pantalla anterior vemos que en el cuadro de búsqueda (1) hay una regla para encontrar todos los DNI (formados por 8 números y una letra mayúscula) y sustituirlos por lo mismo (2). Para poder hacer este tipo de búsquedas y sustituciones, necesitamos activar los caracteres comodín (3).
Con el cursor en cuadro Reemplazar elegimos el estilo DatosSensibles para caracteres (4-6) y pulsamos el botón Reemplazar todos (7). Después repetimos el proceso con los demás datos confidenciales. En algunos casos, como los nombres o apellidos, es posible que no podamos recurrir a búsquedas con caracteres comodín.
Veamos el resultado en el mismo archivo de ejemplo:

Asimismo, si nos atrevemos, podemos grabar una macro de Word para que en el futuro el programa haga todas estas búsquedas y sustituciones de forma automática cuando queramos aplicar el estilo a los datos sensibles.
Importación del archivo en memoQ
Cuando hayamos terminado de ocultar los datos en el archivo DOCX y hayamos guardado los cambios, importamos el archivo en memoQ.
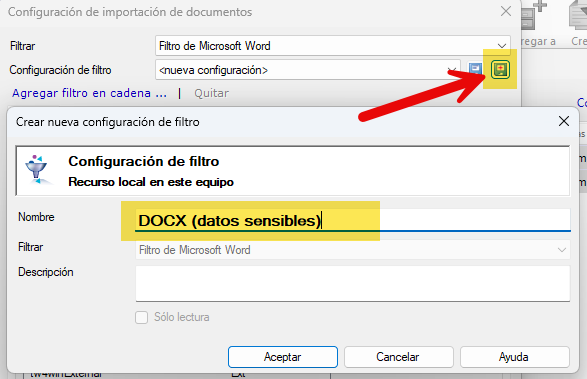
En este caso, necesitamos cambiar la configuración del filtro de archivos DOCX de memoQ para ajustarlo a nuestras necesidades, así que elegimos Importar con opciones.
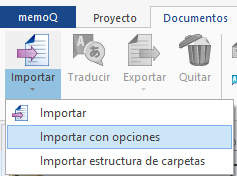
En la siguiente ventana pulsamos Cambiar filtro y configuración.

Acto seguido aparece una ventana con una sección llamada Estilos excluidos donde podemos añadir el estilo DatosSensibles como no traducible.
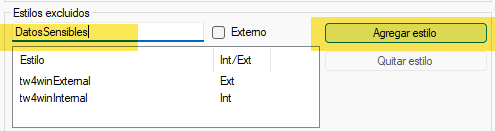
Podemos guardar el filtro modificado con el nombre que queramos y así recuperarlo cada vez que queramos importar archivos DOCX similares.
Los datos sensibles en la vista previa de memoQ
Cuando abrimos el archivo recién importado en un proyecto de memoQ, a priori vemos que ha funcionado como se esperaba, pues los datos sensibles se muestran como etiquetas y no es posible leer el contenido original.
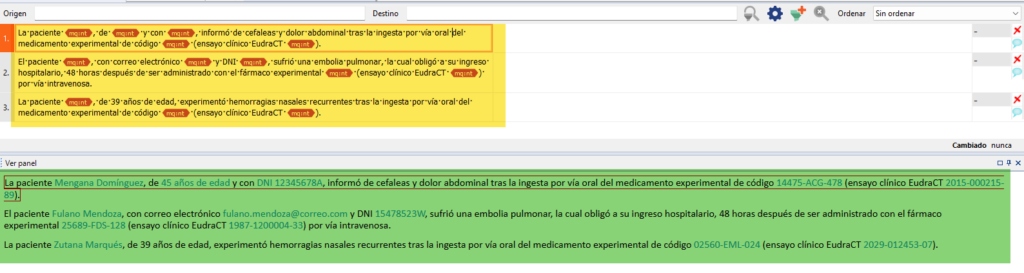
Sin embargo, si prestamos más atención y navegamos por la vista previa de memoQ (señalada en verde en la captura de pantalla anterior), enseguida nos damos cuenta de que los datos sensibles aparecen tal cual, por lo que cualquiera podría acceder a ellos sin demasiado problema si abre el archivo en memoQ. Ante este fenómeno, hay dos opciones para evitar que los colaboradores externos puedan ver esta información.
- Desactivar la vista previa durante la importación de los archivos, lo que imposibilita que incluso quien cree el proyecto pueda ver los segmentos en su contexto.

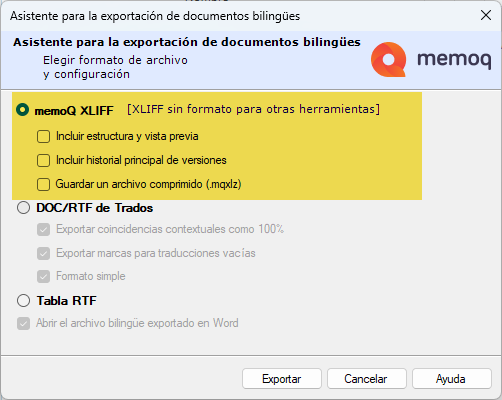
- Exportar los archivos en el formato MQXLIFF bilingüe de memoQ, el cual no incluye la vista previa. Para ello hay que desactivar todas las casillas señaladas en la siguiente captura.
Segundo método: ocultar los datos sensibles en memoQ
El otro método para tratar los datos sensibles que explicaremos en esta entrada consiste en importar el archivo DOCX tal cual y ocultar estos datos en el propio memoQ. Este segundo paso se puede hacer a su vez en dos momentos —durante la importación y una vez importado el archivo—. En cualquier caso, el resultado final será el mismo.
Regex Tagger
Durante la importación del archivo, tenemos que modificar el filtro para archivos DOCX, de modo similar a lo explicado antes. Sin embargo, ahora añadiremos un filtro en cadena para combinar el filtro de DOCX con el de Regex Tagger.
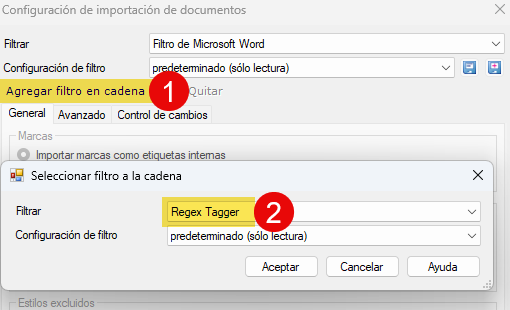
Mediante este sistema, memoQ convertirá en etiquetas las reglas que añadamos usando expresiones regulares.
En la siguiente ventana añadimos la misma regla de antes (1) como una etiqueta vacía, pues no es ni de apertura ni de cierre (2). Como el propósito es que no se pueda saber el dato real, conviene sustituir los datos por otra expresión que funcione como comodín (3). También es conveniente usar un extracto del archivo de origen como texto de prueba (4) para comprobar que nuestras reglas funcionan bien (5).
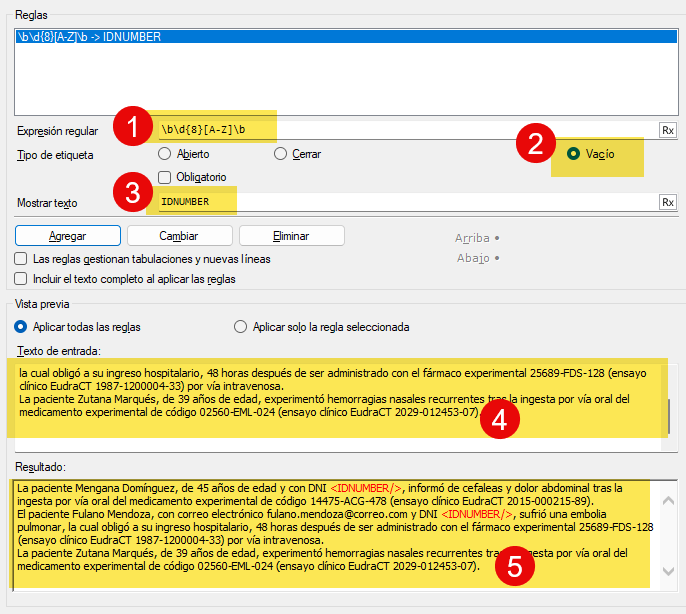
Después repetimos el proceso con las demás reglas. Asimismo, podemos guardar el filtro para reutilizarlo en el futuro.
También contamos con la opción de aplicar Regex Tagger si el archivo ya ha sido importado al proyecto.

En ambos casos, al abrir el archivo importado, tenemos la misma situación que antes: los datos sensibles aparecen como etiquetas en el editor de documentos de memoQ, pero en la vista previa se pueden leer perfectamente.
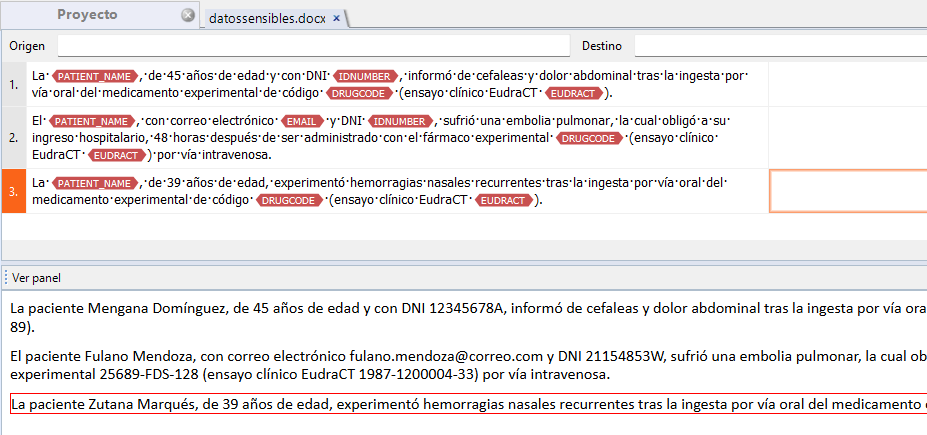
Por tanto, la solución sería desactivar la vista previa según lo comentado antes.
Datos sensibles en los archivos MQXLIFF
Este segundo método cuenta con la ventaja de que siempre se trabaja en memoQ. En cambio, tiene una desventaja que puede suponer un gran problema si enviamos el archivo como MQXLIFF y alguien se pone a investigarlo: los datos sensibles aparecen sin proteger tanto en el segmento de origen como en el de destino. Además, pueden salir varias veces, ya que memoQ almacena el historial de versiones de cada segmento en el MQXLIFF.
Lo podemos comprobar fácilmente abriendo el archivo MQXLIFF en un editor de textos como Notepad++:
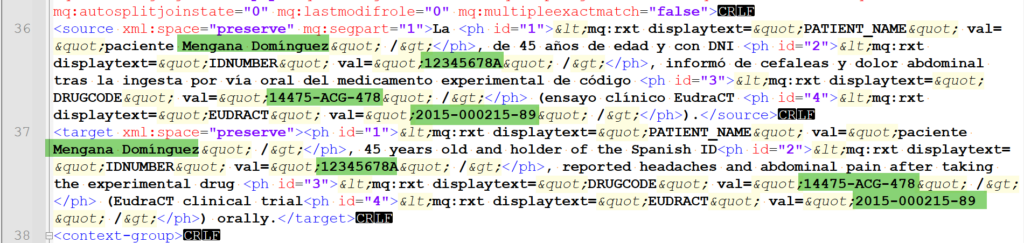
Por lo tanto, este método no sería en absoluto recomendable si queremos compartir los archivos del proyecto mediante MQXLIFF.
Conclusiones
Ciertos archivos de origen contienen datos sensibles que conviene ocultar por cuestiones de confidencialidad. Hay diferentes métodos para hacerlo, los cuales suponen modificar el archivo de origen o bien hacer cambios en la TAO una vez importado el archivo.
Si trabajamos con memoQ y archivos DOCX, podemos crear un estilo en Word para este fin y asignárselo a estos datos. Después solo habría que configurar el filtro de archivos DOCX de memoQ e indicar que ese estilo contiene textos no traducibles.
También es posible aplicar la función Regex Tagger de memoQ para convertir estos datos en etiquetas durante la importación o una vez el archivo ha sido importado en el proyecto.
En ambos casos debemos tener en cuenta que la vista previa de memoQ va por libre y muestra esos datos en bruto, sin ocultar, lo que resulta contraproducente si otra persona se va a encargar de la traducción o de la revisión. Por suerte, se puede solucionar desactivando la vista previa antes de importar el archivo de origen o exportando el archivo como MQXLIFF desde memoQ.
Un inconveniente sin solución es que, si usamos el método de ocultar los datos mediante Regex Tagger, los datos sensibles quedan al descubierto en el archivo MQXLIFF. Por ende, cualquier persona que lo abra con un editor de textos puede acceder a ellos. Este hecho se traduce en una pérdida de la confidencialidad de los datos.
La lección que podemos sacar en claro es que en este tipo de contextos es muy importante no quedarnos con la primera solución que encontremos, sino buscar varios métodos y hacer las pruebas oportunas antes de elegir un proceso u otro para garantizar que la opción elegida sea la idónea en cada contexto.
Deja una respuesta