Hace poco un cliente me escribió para comprobar si un filtro que había creado para procesar sus archivos XML personalizados en Trados Studio funcionaba correctamente. En concreto, me pidió que me centrara en lo referente a las etiquetas bloqueadas.
Estos archivos XML eran el manual de usuario de un programa informático. En dichos archivos se usaba una etiqueta propia para señalar los botones, menús, opciones y otros elementos del software. Algunos de estos elementos se quedaban sin traducir, solo en español. En otros casos, debían ir seguidos de la correspondiente traducción entre corchetes, para lo cual se utilizaba un atributo en concreto, pero la primera instancia siempre debía permanecer en español, por lo cual debía estar bloqueada de algún modo.
Detección del problema
Veamos un ejemplo de estas etiquetas:

En el caso señalado en amarillo, se hacía mención del nombre del programa, por lo que no se debía traducir el contenido. En cambio, sí era necesario en las instancias señaladas en verde, por lo que usaba el atributo formato con el valor bilingue para diferenciarlas del resto de casos.
El filtro a priori funcionaba correctamente tal como lo había recibido del cliente. Tras importar el archivo en Studio y abrirlo en el Editor nos encontrábamos con las etiquetas bloqueadas (como se muestra con el icono del candado):

Sin embargo, tras pseudotraducir el archivo, exportar el XML pseudotraducido y compararlo con el original, se podía detectar a simple vista que el filtro no importaba el contenido traducible en algunos casos:

Una vez comentado este problema al cliente, me pidió corregir el filtro para que importara todo el contenido traducible.
La lógica tras las etiquetas bloqueadas
Antes de ver la solución concreta, conviene saber cuál es la lógica que sigue el programa cuando en un filtro se añaden etiquetas bloqueadas. Para ello, podemos usar un extracto del mismo archivo:

En la anterior captura vemos varios ejemplos de segmentos con estas etiquetas no traducibles en un archivo XML redactado en español. Tenemos dos casos con sendos comportamientos diferentes.
-Por un lado, las etiquetas señaladas en color amarillo no dan quebraderos de cabeza, pues su contenido forma parte de oraciones más largas. Studio no tiene problemas para importar estos segmentos, incluido el texto no traducible y bloqueado.

-Por otro lado, las etiquetas señaladas en azul son ejemplos donde el contenido es el segmento entero. En estos casos, si marcamos esas etiquetas como no traducibles (es decir, como etiquetas bloqueadas), Studio no importa estos segmentos, pues parte de la lógica de que no tiene sentido hacerlo si todo el segmento es contenido que no se debe traducir. Este hecho provoca que, si no se importan estos textos, se quedarán sin traducir (como hemos visto pretraduciendo el archivo), con los riesgos que conlleva.
La solución al problema
Teniendo en cuenta lo comentado antes, mi objetivo era dar con un método para forzar a Studio a importar estos segmentos en todos los casos. Este paso era necesario porque, si bien el contenido dentro de esas etiquetas se iba a quedar en español como etiquetas bloqueadas, debía estar seguido de su traducción entre corchetes.
La solución más sencilla era modificar el archivo XML de origen para duplicar el contenido de dichas etiquetas. De este modo, la primera instancia estaría bloqueada, mientras que podría traducir la segunda.
Así pues, tenía que buscar el modo de que los segmentos formados solo por etiquetas no traducibles se importaran al proyecto en todos los casos. Como explicaremos más adelante, aplicar la primera solución era la clave para poder resolver esta segunda cuestión.
Duplicar el contenido en el archivo XML
Dado que esas opciones de software debían aparecer seguidas de su traducción entre corchetes, lo más lógico era usar regex para modificar el XML de origen y duplicar las etiquetas.
Para la búsqueda usé la siguiente regla:
(<software formato="bilingue">)(.*?)(</software>)
Dicho en lenguaje normal, quería encontrar cualquier conjunto de caracteres situado entre el par de etiquetas software con el atributo formato de apertura y cierre . Gracias a los paréntesis pude agrupar cada uno de los elementos.
Y para la sustitución recurrí a esta regla:
$1$2$3 [$2]
El símbolo del dólar sirve para hacer referencia a cada elemento entre paréntesis del campo de búsqueda, numerados de izquierda a derecha. Mediante esta regla, mantuve los elementos originales en su sitio y después añadí un espacio y el segundo elemento (el texto situado entre las etiquetas software de apertura y de cierre) entre corchetes.
Ante la duda, podemos usar programas como Regex Hero para averiguar si nuestras reglas detectan los casos deseados y si la búsqueda funciona como esperamos:
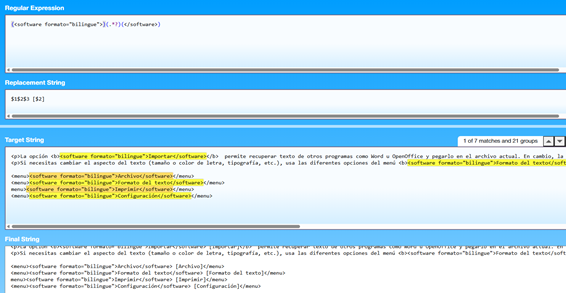
Una vez hecha la comprobación, pude hacer los cambios en el XML usando el editor de textos Notepad++.
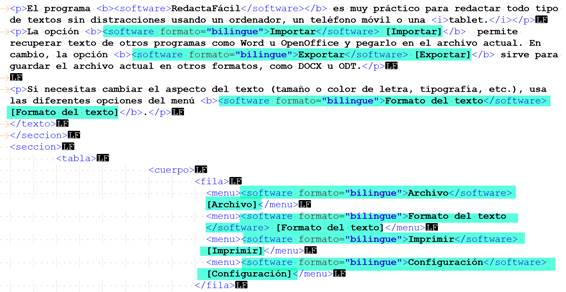
Si estaba en lo cierto, dado que estos segmentos ya no estaban formados únicamente por contenido no traducible, Studio los importaría como etiquetas bloqueadas. Gracias a la vista previa del programa, pude comprobar que mi intuición no fallaba.
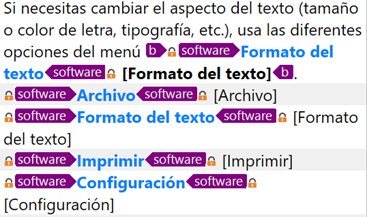
Añadir una regla personalizada en el filtro
Aparte de la solución comentada en la sección anterior, dado que en el archivo XML hay dos versiones de la etiqueta software (una sin atributo y otra con el atributo formato y el valor bilingue), podemos modificar el filtro para que cada una aparezca con un formato diferente (si bien no es estrictamente necesario para resolver el problema original).
Si miramos el filtro del cliente, dentro de la sección Analizador encontramos una regla para todos los casos de la etiqueta software.
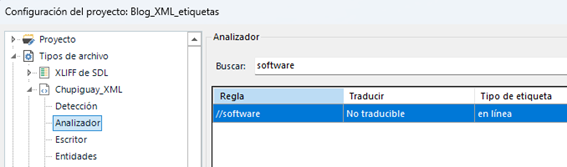
En esta misma sección podemos añadir una regla personalizada de XPath (un sistema para identificar nodos o elementos dentro un archivo XML) para los casos en que la etiqueta software tiene el atributo formato con el valor bilingue (1). Después indicamos que el contenido no es traducible (2) (así aparecerán como etiquetas bloqueadas).
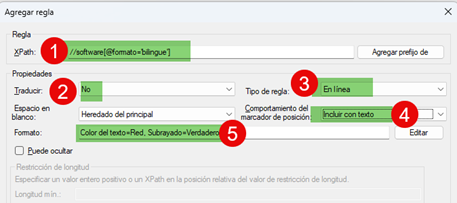
Marcamos este elemento como etiqueta en línea (3) y usamos la opción Incluir con texto para que Studio la muestre en todos los casos (4). Por último, podemos configurar el formato con el que debe aparecer en el Editor de Studio (5).
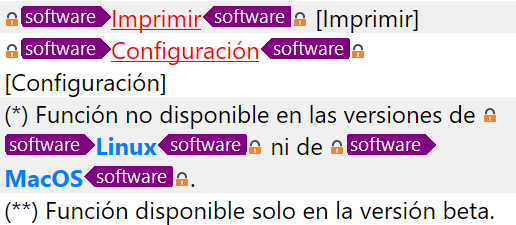
De esta forma, las instancias en que las etiquetas no se deben traducir aparecen en color azul. En cambio, las que deben tener formato bilingüe aparecen en color rojo y con subrayado.
Si tenemos dudas para crear este tipo de reglas de XPath, podemos documentarnos sobre el tema y hacer pruebas en páginas como XPath Tester.
Conclusiones
Cuando recibamos archivos de origen que requieran de un filtro personalizado (nuestro o facilitado por el cliente), es muy importante pseudotraducirlos para comprobar que funcionan correctamente. En caso contrario, sirve para solucionar cualquier problema que surja, ya sea modificando los archivos originales, el filtro u otros ajustes de la herramienta TAO.
En este proyecto, la pseudotraducción sirvió para detectar que el filtro no importaba algunos textos traducibles si se habían configurado ciertos contenidos como etiquetas bloqueadas. De no haberla llevado a cabo, es muy probable que no se hubieran detectado estos problemas hasta una vez comenzada o incluso terminada la traducción.
Por otro lado, dadas las peculiaridades de este archivo en concreto (etiquetas no traducibles que debían aparecer con un formato bilingüe), la forma más rápida de garantizar que todos los segmentos traducibles fueran importados en Studio consistía en duplicar el texto de las etiquetas en el propio XML. El hecho de conocer regex, incluso sin dominarlo en profundidad, ayudó a que se pudiera hacer esa duplicación sin complicarnos la vida.
Por último, también es recomendable saber cómo funcionan los filtros de las herramientas TAO (Studio, en este caso) para que podamos modificarlos según nuestras necesidades.
Deja una respuesta