La entrada anterior de Melodía de traducción me sirvió para comentar que, por cosas del destino, en la actualidad llevo a cabo prácticamente todas mis tareas usando memoQ. En esta línea, la entrada que hoy publico versa sobre las vistas de memoQ y su utilidad de cara al trabajo diario, para lo cual recurriré a la ayuda de unos cuantos ejemplos prácticos.
Oiga, ¿pero qué es eso de las «vistas»?
Según la ayuda de memoQ, las vistas son recolecciones de segmentos extraídas de los archivos traducibles mediante distintos filtros o clasificaciones. Dicho de otra forma, las vistas se pueden entender como filtros avanzados que permiten aislar segmentos o fusionar segmentos de diferentes archivos de un proyecto de traducción en función de lo que necesitemos. Aunque más adelante lo veremos con mayor detalle, varios usos prácticos de la vistas van desde la fusión de varios archivos en uno solo hasta la división de un archivo en varios subarchivos para su traducción por parte de varios traductores, ver todos los segmentos con errores de un proyecto, eliminar etiquetas sobrantes (es decir, que no forman parte del segmento de origen) tras la pretraducción de uno o varios archivos —como, por ejemplo, las procedentes de segmentos importados en una memoria de traducción procedentes de un TMX creado con otra herramienta TAO—, comprobar si la traducción de un término (no necesariamente parte de una base de datos terminológica), etc. A nuestro alcance queda, por un tanto, un gran abanico de posibilidades para gestionar nuestros proyectos de un modo más cómodo y productivo.
Otro punto a favor de las vistas es la posibilidad de elegir entre traducirlas directamente con memoQ o exportarlas, bien añadiéndolas al corpus asignado al proyecto o bien como archivos bilingües. Si echamos un vistazo a esta segunda opción (a la que llegamos haciendo clic con el botón secundario sobre la vista y eligiendo Exportar archivos bilingües), vemos que hay tres opciones posibles, como se aprecia en la siguiente captura de pantalla).
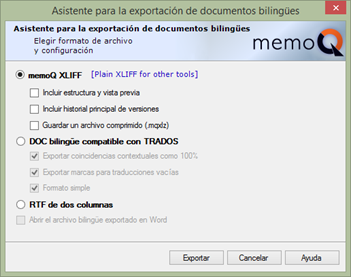
Asistente de exportación de archivos bilingües en memoQ
De las tres opciones, el formato MQXLIFF (una variante del estándar XLIFF empleada por memoQ) y el DOC bilingüe (el formato clásico usado por versiones de Trados anteriores a SDL Trados Studio 2009) sirven para poder enviar las vistas a otros traductores que no dispongan de memoQ pero sí de alguna otra herramienta TAO. Por su parte, el RTF a dos columnas es más útil para la revisión de la traducción mediante control de cambios en Word. Sea cual sea el que elijamos, una vez lo recibamos actualizado por parte del traductor o revisor, lo podremos importar de vuelta en memoQ mediante el paso contrario. De esta forma, nos aseguraremos de que las vistas incluyan todos los cambios y, por ende, de que los documentos principales a partir de los cuales obtuvimos las vistas queden también actualizados.
No obstante, hay que tener en cuenta varias cuestiones cuando se trabaja con vistas. En primer lugar, cualquier cambio que se haga en la vista tiene su efecto en los documentos principales de donde procedan los segmentos, con lo cual garantizamos que el proyecto se actualiza constantemente. Por esta misma razón, no es posible abrir los archivos traducibles y sus vistas correspondientes al mismo tiempo, ni realizar cambios en segmentos que ya pertenezcan a alguna vista, como separarlos en varios segmentos o fusionar dos o más segmentos en uno solo (lo que sí se puede llevar a cabo dentro de una vista si los segmentos pertenecen al mismo archivo principal). De esta forma, se busca que la traducción sea coherente tanto en el documento principal como en la propia vista.
Vale, ¿y cómo creo una vista? ¿Y cómo la exporto?
El proceso para crear una vista es bien sencillo. El primer paso consiste en crear un proyecto e importar los archivos que queremos traducir de la forma habitual. Una vez terminado el proceso, vamos a la sección Traducciones, donde veremos todos los archivos que conforman el proyecto. Ahora basta con señalar todos los archivos con el atajo Ctrl + Mayús. + A o, en su caso, solo los que nos interesen dejando pulsada la tecla Ctrl a la vez que hacemos clic con el ratón. Acto seguido, hacemos clic con el botón secundario y, como se señala en la siguiente captura de pantalla, elegimos la opción Crear vista.
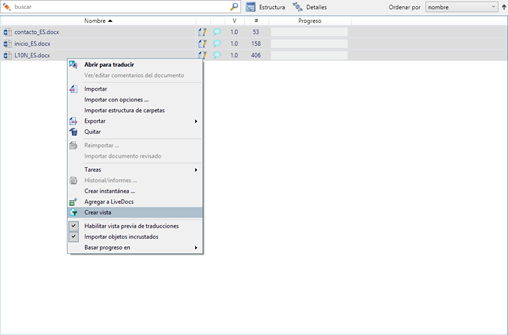
Creación de una vista a partir de varios archivos
Llegados a este punto, solamente queda elegir las opciones correspondientes en cada caso y dar un nombre a la vista lo más descriptivo posible (por si acaso olvidáramos lo que pretendíamos conseguir con esa vista en concreto). Cuando termine el proceso, la vista recién creada aparecerá en la pestaña Vistas. Si queremos exportar una o más vistas, basta con seleccionarlas, hacer clic con el botón secundario del ratón y elegir la opción de exportación que necesitemos.

Exportación de vistas como archivos bilingües en memoQ
Algunos casos prácticos
Después de la siempre poco entretenida teoría, llega el turno de pasar a los casos prácticos con las vistas en memoQ con el propósito de entender mejor lo que es posible lograr si recurrimos a ellas. A continuación, os pondré varios ejemplos de diferentes usos de las vistas.
1. Fusionar varios archivos en uno
Esta es la opción predeterminada de memoQ a la hora de crear vistas (Solamente pegar los documentos). Es de utilidad para hacer más manejables proyectos formados por decenas de archivos muy pequeños, o bien para evitarnos el tener que enviar muchos archivos a un traductor o revisor externo (lo que podría suponer que alguno se extraviara o se quedara sin traducir o revisar), en especial si no utiliza memoQ.
2. Dividir un archivo en varios subarchivos
Si queremos dividir un archivo en varias partes, tendremos que escoger la opción Dividir documento (como se ve en la captura de pantalla) y crear tantas vistas como partes en que vayamos a dividirlo (es importante comprobar que no nos dejamos fuera ningún segmento). Al contrario que en el primer ejemplo, hay proyectos con archivos muy grandes y plazos ajustados, cuya traducción o revisión la llevarán a cabo varias personas.

División de un archivo en varios partes según el número de segmentos
Como nota negativa, no podemos crear partes con el mismo número de palabras de forma fácil —lo cual agilizaría mucho la preparación del proyecto y lo que sí es posible en proyectos gestionados en un servidor con la versión Project Manager—, sino que habrá que jugar con el número de segmento tanto de inicio como de cierre, e ir haciendo el recuento de palabras a medida que creemos las vistas. Sin embargo, otra de las novedades de memoQ a partir de la versión 2014 es que muestra de forma predeterminada el número de palabras de cada archivo en vez del número de segmentos, lo cual puede ser contraproducente para nuestros intereses, pues cabe la posibilidad de que algún segmento se quede fuera de las vistas y, por lo tanto, sin traducir. Para evitar males mayores, si vamos a Opciones > Varios > Mostrar el progreso (%) de la traducción basado en… y marcamos la opción Segmentos (tal y como se muestra en la siguiente captura de pantalla), averiguaremos cuántos segmentos tiene cada archivo y cada vista.
Ver el número de segmentos de un archivo
3. Eliminar etiquetas sobrantes después de pretraducir
El siguiente ejemplo resulta práctico cuando pretraducimos archivos con memorias de traducción cuyos segmentos proceden de otras herramientas TAO. Como cada una de ellas tiene su propia forma de «interpretar» el texto y de añadir las etiquetas, a veces me he encontrado con etiquetas en segmentos pretraducidos que no aparecen en el segmento original correspondiente en memoQ. Sin embargo, dado que otra herramienta entendió que debería haber una etiqueta en dicho segmento, la traducción también la tenía, ergo el TMX creado a partir de esa memoria también lo tenía. En el caso de memorias obtenidas con archivos traducidos con Trados, memoQ no suele tener problemas y oculta bastantes etiquetas (siempre que indiquemos que el TMX procede de Trados cuando lo importemos en memoQ), aunque casi siempre detectaremos que alguna se escapa. Si hay un gran número de segmentos con este problema, tener que estar pendientes de borrarlas en memoQ nos llevará mucho tiempo y, además, es posible que se nos pase alguna por alto.
Con el propósito de ilustrar esta situación, he creado un proyecto con tres archivos DOCX muy cortos que había alineado previamente, alineación a partir de la cual he obtenido una memoria en formato TMX que he importado después en la memoria de memoQ asignada a dicho proyecto. El siguiente paso ha consistido en pretraducir los archivos y bloquear las coincidencias del 100 % (pese a que bloquear los segmentos no es estrictamente necesario, yo prefiero hacerlo así). A modo de repaso, a la pretraducción se accede en la pestaña Preparación, botón Pretraducir. Para bloquear los segmentos, tenemos que marcar la casilla Bloquear filas en la pestaña Confirmar/bloquear en la ventana que aparecerá a continuación.
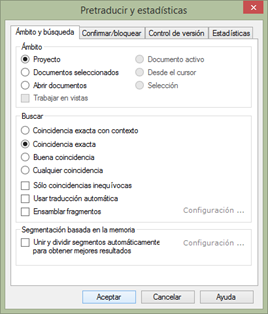
Pretraducción en memoQ
Una vez pretraducidos los archivos, he creado la vista de la forma habitual, aunque en este caso las opciones que me interesaban están en Opciones avanzadas. Dado que he bloqueado los segmentos y que la presencia de etiquetas en el segmento de destino que no se encuentren en el segmento de origen causa un error al intentar obtener los archivos finales, he marcado esos dos delimitadores en la pestaña Estado perteneciente a la sección Filtrar por estado del segmento.

Filtrar por estado del segmento
La vista resultante consta, como se puede ver en la captura de pantalla de la izquierda, de tres segmentos. Para poder borrar las etiquetas, es necesario desbloquearlos (en su caso). Para tal fin, seleccionamos todos con la combinación Ctrl + Mayús. + A y luego los desbloqueamos con el atajo Ctrl + Mayús. + L. En este punto, podemos quitar todas las etiquetas de un plumazo si pulsamos la combinación Ctrl + F8 o si vamos a la pestaña Editar, grupo Etiquetas, menú Comandos de etiqueta, opción Quitar todas las etiquetas (véase la segunda captura de pantalla a continuación).

Vista de segmentos bloqueados con errores
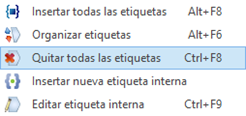
Quitar todas las etiquetas de varios segmentos
Si abrimos los archivos principales de donde proceden los segmentos, como en la siguiente captura de pantalla, notaremos que los segmentos ya no tienen las etiquetas procedentes del TMX.

Segmento tras borrar todas las etiquetas
Gracias a esta vista, hemos solucionado de una forma muy rápida lo que habría sido una tortura, en especial en proyectos grandes. Solo queda volver a bloquear los segmentos (en su caso) para poder seguir trabajando con normalidad y sin mayores preocupaciones.
4. Bloquear segmentos en destino formados solo por etiquetas
Al importar un archivo, puede darse el caso de que memoQ cree segmentos formados solamente por etiquetas, los cuales, como es lógico, se quedan igual en la traducción. Con el fin de preservar la integridad del archivo y de asegurarnos de que podremos exportarlo sin problemas una vez hayamos acabado la traducción (en especial si se la vamos a encargar a otro traductor), resulta interesante el crear una vista que contenga solo este tipo de segmentos, que después bloquearemos para que no sea posible modificarlos.
memoQ permite crear vistas que contengan solo los segmentos con etiquetas en el segmento de destino. Si hemos pretraducido los archivos como en el tercer ejemplo pero no hemos llegado a eliminar las etiquetas, estos segmentos pretraducidos también aparecerán en esta nueva vista. Si queremos asegurarnos de que aparezcan los segmentos formados exclusivamente por etiquetas, podemos añadir la opción de que la vista incluya segmentos no bloqueados —lo cual funcionará, como es obvio, si hemos bloqueado los segmentos al pretraducir—. Esta captura de pantalla muestra mejor cómo crear esta vista.
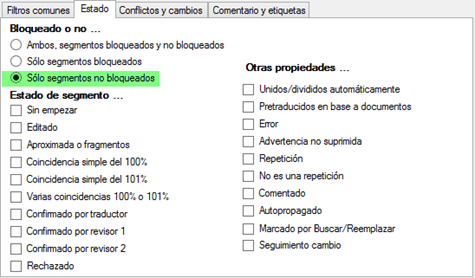
Filtro para obtener solo segmentos no bloqueados
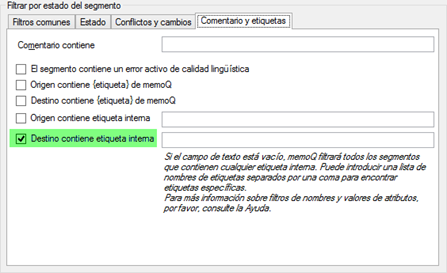
Filtro para obtener solamente segmentos de destino con etiquetas internas
El resultado de crear la vista, elegir todos los segmentos y bloquearlos es el que se aprecia en la siguiente captura de pantalla:

Segmentos formados únicamente por etiquetas tras ser bloqueados
5. Aplicar expresiones regulares en determinados segmentos
Para la última aplicación práctica de las vistas que veremos en esta entrada, vamos a partir de varios supuestos:
- Los archivos de origen contienen segmentos con etiquetas personalizas que aparecen como texto normal porque no hemos creado un filtro personalizado para dichos archivos;
- Queremos convertir ese texto normal en etiquetas de memoQ para que no lo podamos modificar con la ayuda de expresiones regulares;
-
Por las razones que sean, solo queremos aplicar las expresiones regulares en ciertos segmentos o en ciertos archivos.
Así pues, procederemos a crear una vista que aísle solamente segmentos con etiquetas personalizadas de archivos concretos de un proyecto. A continuación, aplicaremos las expresiones regulares a la nueva vista para convertir ese texto normal en verdaderas etiquetas de memoQ.
En primer lugar, importamos los archivos de origen del modo normal y, al abrir uno de ellos, veremos que hay unas etiquetas personalizadas que memoQ ha dejado como texto traducible:

Etiquetas como texto normal en memoQ
Así pues, vamos a suponer que no queremos cambiar ese texto en todos los archivos. Bastará, en este caso, con seleccionar los archivos en la lista de documentos y crear una vista usando como criterio que se muestren solamente los segmentos en cuyo idioma de origen estén las etiquetas que queremos convertir. El siguiente paso es abrir la vista recién creada para después usar las expresiones regulares con el objetivo de indicar a memoQ que tiene que tratar esos textos como etiquetas. Para tal fin, vamos a la pestaña Preparación, sección Otro y opción Regex Tagger.
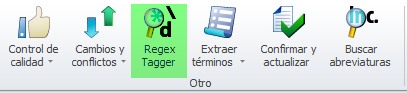
Regex Tagger en memoQ
Aparecerá ventana donde tendremos que escribir la expresión regular. En este caso, dicha expresión es muy sencilla: <.*?>. El campo Mostrar texto lo dejaremos tal cual aparece. En el recuadro Resultado se puede observar la vista previa de los elementos a los que engloba la expresión regular, los cuales están marcados en color rojo para su mejor identificación.

Reglas mediante expresiones regulares en memoQ
A continuación, pulsamos Aceptar y enseguida notaremos el efecto de la expresión regular, tal como se ve en la siguiente captura. Si abrimos el documento principal a partir del cual creamos la vista, descubriremos que memoQ ha aplicado los cambios directamente en los mismos segmentos.

Etiquetas tras aplicar las reglas de expresiones regulares
Cómo trabajar con vistas usando otras herramientas TAO
Para terminar con esta entrada, vamos a describir cómo exportar una vista a un formato compatible con otras TAO, como SDL Trados Studio 2014. En primer lugar, seleccionaremos la opción Exportar archivos bilingües y, entre las tres opciones disponibles, elegiremos MQXLIFF y desmarcaremos las tres casillas para asegurarnos de la plena compatibilidad con otras herramientas TAO.
Obtendremos así un archivo MQXLIFF que se traducirá con la herramienta que prefiramos. Así aparecería en SDL Trados Studio 2014:

Archivo MQXLIFF abierto en SDL Trados Studio 2014
Lo que viene es muy sencillo: traducimos el texto y lo exportamos de vuelta al formato original en función de la TAO que hayamos usado. Después, si todo va bien, lo importamos en memoQ y automáticamente memoQ detectará que se trata de una actualización y así lo mostrará, como vimos anteriormente. Si lo abrimos, veremos la traducción actualizada:
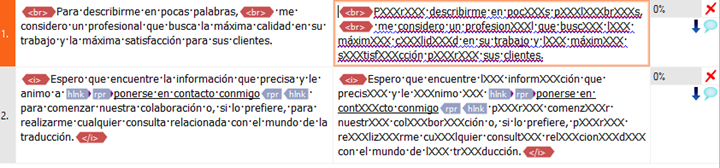
Archivo actualizado tras importar la traducción de otra TAO
Conclusiones
Si habéis llegado hasta aquí, seguro que os habréis dado cuenta del tremendo potencial de las vistas en memoQ. Esta entrada solamente pretende mostrar su gran utilidad, pues las vistas sirven para multitud de fines, se pueden personalizar en función de nuestras necesidades en un proyecto en concreto, nos pueden sacar de más de un apuro y evitarnos quebraderos de cabeza. Además, se pueden combinar con Word y otras herramientas TAO sin apenas tener problemas.
Y vosotros, ¿las usáis en vuestros proyectos? ¿Para qué fin? No seáis tímidos: compartid vuestra sabiduría en un comentario. 🙂
Es muy útil y de gran ayuda para los traductores que carecen de conocimientos al respecto.
Gracias por el comentario, Vanesa. No dudes en preguntar si tienes alguna duda. 😉
Gracias por compartir!
Me estreno como traductora en diferentes proyectos con distintas agencias de traducción y me viene genial conocer todas estas herramientas…
Esperando ya la siguiente entrada!
Hola, María:
Me alegro de que te sirvan de ayuda mis entradas. 🙂
En breve estaré menos liado y tendré tiempo para preparar las nuevas entradas que tengo en mente. Espero que te gusten. 🙂